Unpacking the encoder, decoder and the building blocks of AI

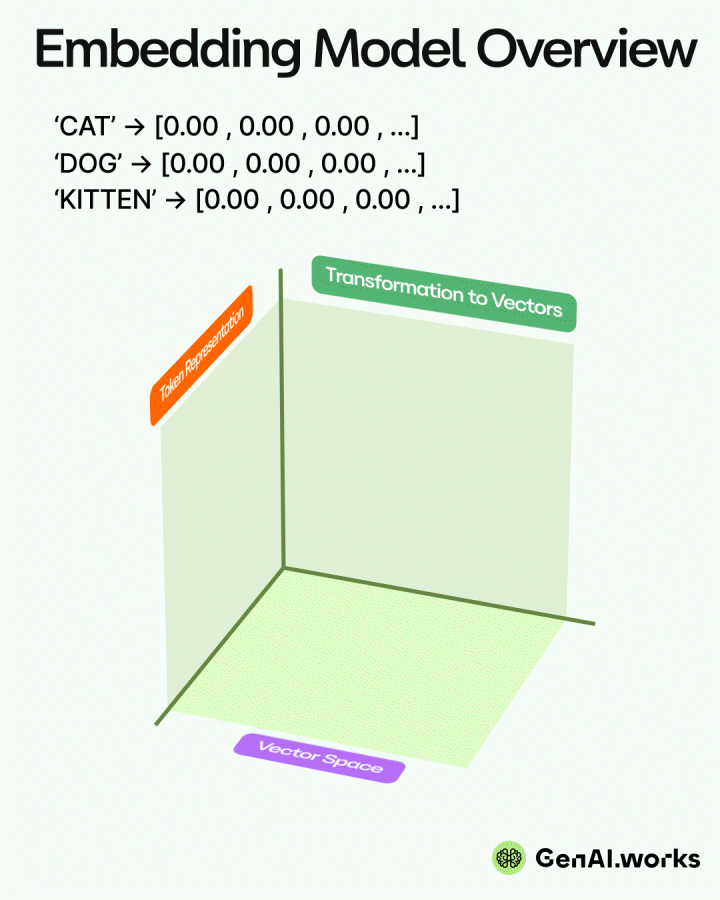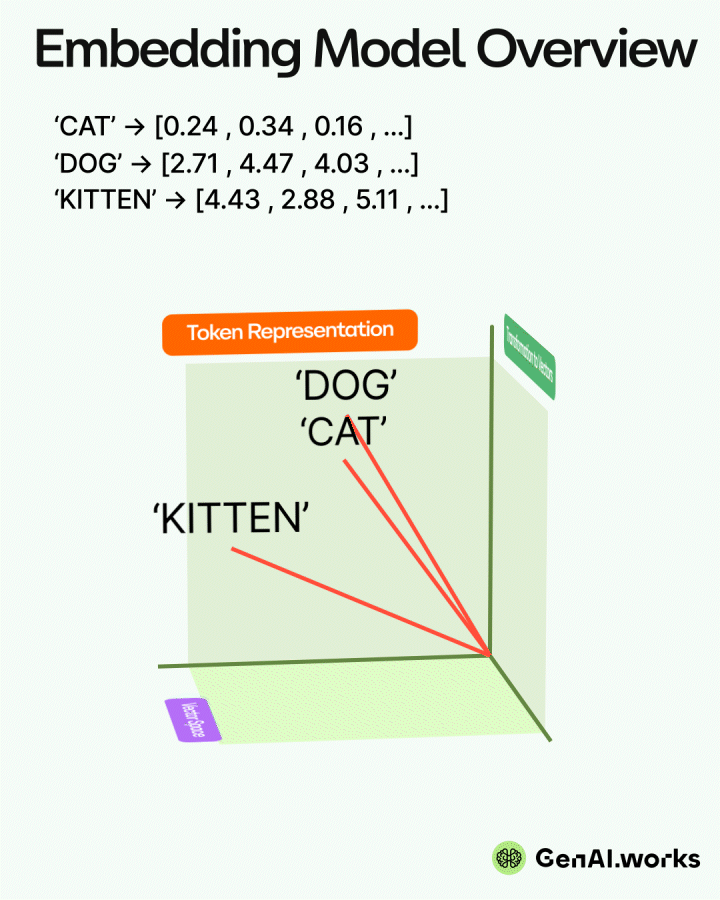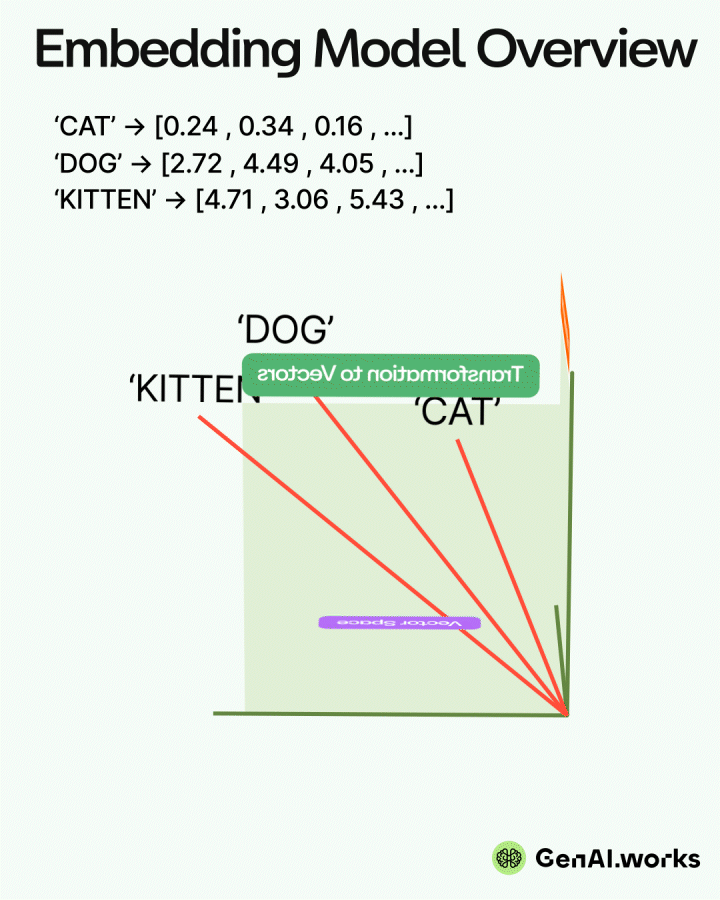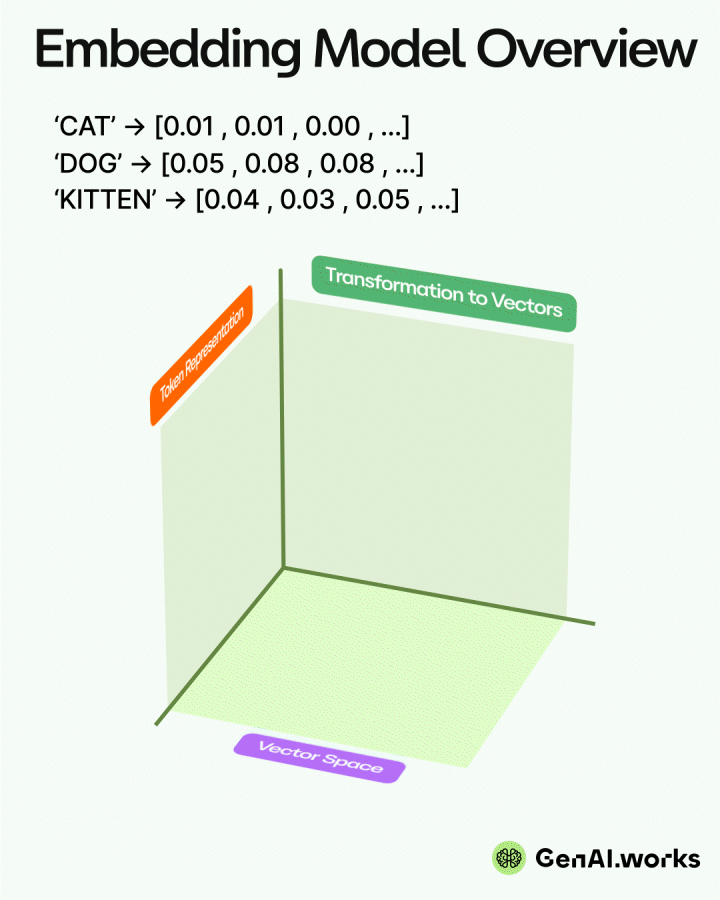


A guide to open-book strategy that helps your AI give accurate answers

The AI landscape shifts daily. For founders, operators, and business leaders, the challenge is no longer finding information — it's filtering it. The difference between a distracted strategy and a competitive advantage often lies in the quality of your information diet. Here are ten AI influencers on LinkedIn in 2026 who consistently deliver signal over noise.